|
目前的IT应用中,有一“小”一“大”是几乎所有人关注的焦点。 “小”是前端的移动,虽然设备的尺寸在逐渐变大(如不久前推出的iPhone 6 Plus),总的来说还是比PC/Mac小很多,关键是操作习惯不同,强调简洁和随时随地使用;“大”是后端的大数据,不仅仅是数据大、多样性,更重要的是追求数据的全集而非子集,特别是从历史数据中发掘价值。 有厂商将为传统应用设计的平台称为记录交易系统(systems of record),为新一代应用设计的平台称为互动参与系统(system of engagement)。划分不是很严谨,兼具二者特性的新平台亦非鲜见。不过,每一笔交易都会产生交易记录,这些在传统应用中已经成为历史的数据,可以被新一代应用拿来做离线分析,供定向广告、精准营销等应用。日积月累下来,互动参与系统的数据增长率显然更高,数据吞吐量也非记录交易系统可比,即要求大容量、高带宽。 典型记录交易系统处理的数据量不算大,但对延迟要求较高,类似需求在新一代应用中只多不少: 一方面,电子商务的蓬勃发展,让人们的交易更方便快捷。以前交易的瓶颈通常在窗口/柜台,排队的是人;现在每个人的手机/平板或PC/Mac都可以成为窗口/柜台,随时随地发起交易,排队转到服务器里进行,峰值时交易请求量提高多少数量级,如淘宝+天猫的双11,以及春节前后的12306——挤爆点由售票大厅,换成了服务器…… 另一方面,在移动时代,人们更加缺乏耐心,一个页面或App两三秒还没有加载内容,可能就要关掉“走人”了;12306的票刷不出来还可以忍,“光棍节”的失败则是阿里巴巴无法承受的。大量I/O请求时仍要保证延迟不超标,互联网应用面临的挑战是全方位的。
简而言之,除了传统的容量和IOPS,新一代应用需要存储(子)系统在带宽和延迟上也有很好的表现,而这是传统存储难以满足的。 传统存储的局限 存储作为一个独立的行业存在,很大程度上得益于80年代初的硬盘驱动器(HDD)小型化浪潮。在此之前,基本上每家主机厂商都有自己的硬盘(驱动器)业务。如今最大的存储公司EMC,和很长时间内作为最大硬盘公司的希捷(Seagate),均创立于1979年,不能完全以巧合来解释。 大尺寸硬盘可以提供更大的容量和更高的顺序传输性能,小尺寸硬盘在随机I/O上的表现更好。即使提高转速、缩短寻道时间,单个硬盘的IOPS(I/O per second,每秒I/O操作数)也有限(在二三百的量级),要获得更高的IOPS,就必须尽可能多的增加硬盘数量,而服务器内部空间是有限的。使用专门的存储设备则不受此限制,而且还可以通过SAN(Storage Area Network,存储区域网)被多台服务器共享。 与直接连到服务器内部的方案(DAS,Direct Attached Storage)相比,存储网络增加了延迟,带宽也相对有限。不过,在硬盘时代这都不是大问题:延迟方面,响应速度在毫秒(ms)级的硬盘才是瓶颈;带宽方面,每个交易的I/O块都不大,以4KB计,每个硬盘也就是1MB/s左右的输出,就是有几千个硬盘一起工作,又能有多少呢? 闪存技术的成熟,彻底改变了游戏规则。 英特尔公司非易失性存储器(NVM)解决方案事业部市场总监Peter K. Hazen曾经给过一个非常直观的比喻:从旧金山飞到北京需要大约11个小时,如果说这是硬盘的速度,那么,换成基于闪存的固态盘(SSD,Solid-State Drive),只需要1分钟。 延迟和IOPS是闪存的强项,别说600多倍,千倍的理论指标都有。而从实际应用来看,SSD在硬盘的百倍之上,通常是可以保证的。 当SSD的访问延迟(latency)可以低至几十微秒(μs),通过存储网络访问的延迟就不能再忽略不计了;当单个SSD随机I/O访问的输出都能填满一条8Gb/s FC(8GFC)主机通道,主机和存储之间的带宽也可能成为瓶颈了。 特别是,当几个SSD就能满足一台服务器对I/O能力的需求时,用户为什么还需要外接磁盘阵列呢?除了容量… 作为存储行业的领头羊,EMC很早就意识到了变革的来临。EMC不仅在存储厂商中率先拥抱SSD,还给出了上述问题的解决之道:要么让存储靠近计算,要么让计算靠近存储。 第一条好实现——把存储重新塞回服务器里去(并不是EMC表达的原意)就行了…第二条呢? Oracle给出了一个范例。 Exadata的早期启示 2008年上半年,EMC在其高端存储Symmetrix DMX-4里引入了SSD;下半年,Oracle联合惠普推出了数据库一体机Exadata的“前身”。 说是前身,一则Exadata只是存储服务器的名字,而一个整机柜最多有8个数据库节点和14个Exadata存储服务器组成,全都是HP基于英特尔至强(Xeon)CPU的服务器,通过高速InfiniBand(IB)互连;二则定位为数据仓库设备,不适于OLTP应用。 道理很简单,数据仓库系统中以英特尔为代表的x86处理器是主流,更关键的是OLAP应用以批量传输为主,只要不频繁的随机访问,硬盘的吞吐量并不算差。如果是OLTP应用,14个存储服务器的100多个硬盘不够用,20多个至强CPU又显浪费——因为要的就是IOPS。 然而,Oracle之所以用存储服务器,要的就是里面的CPU,以实现让计算靠近存储的目标,为网络和数据库服务器减负。 计算靠近存储的一个典型好处就是,在靠近数据的地方处理,直接返回结果,而不是传输大量的原始数据到服务器去处理,这在原始数据集很大,而处理结果很小的情况下效果尤为明显,可以避免大量网络传输的开销。虽然Exadata采用高速的InfiniBand,但首要是利用其低延迟的特性,再高的带宽,传输大量数据也需要耗费时间啊。Exadata不同于一般的Oracle RAC,很重要的一点就在于其内置智能扫描(Smart Scan)处理技术,将一些简单的查询工作卸载到存储服务器,“通过把扫描处理从数据库中剥离,减少了数据库服务器的CPU负担,同时极大降低了无效的信息传输——仅仅传输需要的有价值的信息”。理论上从数TB的表中返回几MB的数据到数据库服务器,意味着多大的节省…总之,可以明显提高OLAP应用的效率。 2009年初,Oracle收购了Sun,半年后推出“根正苗红”的Exadata。之所以这么说,一是Exadata正式成为整个一体机(融合系统)的名称,二是服务器全都换成自家的SunFire x86服务器——都基于英特尔至强,能有多大差别?所以,真正重要的变化是,由于在存储服务器中引入了PCIe闪存卡作为Smart Flash Cache,极大地提高了I/O性能,使Exadata也能胜任OLTP应用,而不仅仅是一款数据仓库设备。

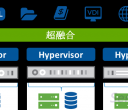
从2009年的Sun Oracle Database Machine (V2)加入闪存开始,Exadata就不再局限于数据仓库 英雄所见略同,阿里巴巴和淘宝的技术团队的“去IOE”运动也是类似的思路。我们知道,IOE分别是IBM、Oracle、EMC,更确切地说是IBM小型机、Oracle数据库与EMC存储设备的组合,这三驾马车构成了一个从软件到硬件的完整商用数据库系统。不过,严格说来,支付宝并没有去O——毕竟Oracle数据库是交易型应用的首选——甚至还保留了“少量”的E用来存储Redo日志,但主体已经是PC服务器+闪存的架构。 如果说去大I(BM)是小i(ntel)的胜利,那么去E(MC)就是闪存的胜利。 超融合系统的崛起 虽然Exadata专门用在交易型系统的比例不算高,但它起码证明了分布式(通过ASM)、横向扩展(Scale-out)存储架构和闪存,在企业关键业务应用中是完全可行的。 不过,Exadata的计算和存储还是分离的。存储服务器毕竟计算能力有限,不像数据库节点,都是同系列中顶配的CPU——如去年12月中旬发布的Exadata X4-2,用的是当时至强E5系列中顶级的E5-2697 v2,而存储服务器的CPU型号则“羞于一提”。如果把计算和存储一体化,或曰“存储重新塞回服务器里去”呢? 相对于通过网络把服务器与存储连接起来的传统融合系统,超融合系统(hyper-converged system)实现了计算和存储一体化的回归(Exadata介于二者之间),代表作是Nutanix的Virtual Computing Platform(虚拟计算平台)。 Nutanix成立于2009 年(在本文中,这是一个很重要的年份),于2011 年推出一体机NX 家族,硬件平台是Supermicro的2U密度优化型服务器,支持1-4个双路英特尔至强节点,融合了计算与存储。软件上,得益于Google的成果,Nutanix采用著名的MapReduce分布式计算框架,配以类似GFS的NDFS(Nutanix Distributed File System,Nutanix 分布式文件系统)——更著名的模仿者当然是Hadoop。 
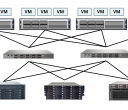
Nutanix虚拟计算平台的横向扩展架构 正如“虚拟化计算平台”这个名字所显示的,每个节点上运行VMware vSphere、微软Hyper-V或可选的KVM,以承载控制功能(CVM)和应用(User VM,用户虚机)。每个节点上有一个起控制器作用的虚机(Controller VM,CVM),以Pass-through(直通)方式下穿hypervisor 层,访问连在SAS控制器上的硬盘和SSD。 CVM 响应所在节点上用户虚机的I/O请求,并提供自动精简配置(Thin Provisioning)、自动分层存储、重复数据删除(De-dupelication)、复制和快照等高级功能,所有CVM 共同参与整个集群的管理。该架构最大的特点是数据本地化,缩短响应时间,降低网络流量,利于横向扩展到规模更大的集群。通过控制算法保持数据在距离最近的地方,并允许写I/O 操作在同一节点本地化。 如果VM 迁移到另一台主机,数据也将跟随VM 自动迁移以保证最高性能(维持存储靠近计算)。当某个VM有一定量的读请求发向其他节点上的控制器,Nutanix ILM将透明地移动远端数据到本地控制器,以保证读I/O 在本地完成,而不是通过网络。如果一个CVM 失效,所有I/O 请求都自动转发到另外一个CVM,直到本地CVM 重新可用。这个Nutanix 自动路径技术完全对hypervisor 层透明,用户VM继续正常运行。如果整个节点故障,HA 事件自动触发,VM 将自动迁移到集群内的另一台主机上。同时,数据被再次复制以维持复制因子(指定的副本数量),及整体的可用性。 Nutanix的融合系统体现了来自互联网的(Web-Scale)技术与传统企业级技术的结合,使用NDFS实现存储层的横向扩展,虚拟化负责计算层的横向扩展,并对控制功能的横向扩展有所贡献。 如同Exadata可以运行在HP或其他x86服务器上一样,Nutanix融合系统的核心也是运行在商用硬件(Commodity Server)上的软件,软硬件可以分开销售——譬如Nutanix已与戴尔(Dell)公司达成OEM合作,在Dell(服务器)硬件上转售Nutanix的超融合存储软件。据悉,Dell近期将推出基于至强E5 v3、类似Supermicro Twin家族的密度优化型服务器,正是Nutanix喜欢的那一类平台。 巨头们的反击 Nutanix不是唯一的超融合系统初创公司,但其在市场上的成功引来了大公司的效仿。2013年8月底发布VSAN(Virtual SAN)之后,VMware填补了存储软件上的空白(再早的vSphere Storage Appliance太弱,母公司EMC也指望不上)。仅过了一年时间,VMware就发布了其超融合基础设施设备EVO:RAIL。 当然,VMware还没必要亲自上阵做硬件,类似于Nutanix与Dell的合作,EVO:RAIL是一个参考设计,它要求一个捆绑了计算和存储的2U四节点密度优化型服务器,要求每个节点(不低于): 双路英特尔至强E5-2620 v2 6核CPU(当时E5 v3尚未正式发布) 192GB内存 1个SLC SATADOM或SAS硬盘作为ESXi引导设备 3个SAS 10000RPM 1.2TB硬盘用作VMware Virtual SAN(VSAN)数据存储 1个400GB MLC企业级SSD用于读写Cache(读缓存/写缓冲) 1个Virtual SAN认证的直通(pass-through)磁盘控制器 2个10GbE网口(可配置为10GBase-T或SFP+连接) 1个1GbE IPMI端口用于远程(带外)管理
EVO:RAIL V1.0可以横向扩展至4个设备的集群,也就是16个节点,这显然是受限于VSAN的能力。随着VSAN走向成熟,VMware将以其在业内的特殊地位,联合EMC、富士通、浪潮等硬件合作伙伴如对其他初创公司展开“围剿”。 
VMware EVO:RAIL设备的基本构成 上面那个本应都是服务器厂商的名单里,出现了VMware的母公司EMC,比较有趣。这倒不是说EMC没有服务器硬件产品,EMC的高端(Symmetrix VMAX)、中端(VNX)存储系统的控制器,技术含量比一般的x86服务器更高,EMC要做服务器硬件没有难度,何况其还加入了Facebook发起的开放计算项目(Open Compute Project,OCP,VMware在发布EVO:RAIL之前宣布加入),实在不行直接拿个服务器设计过来也是可以的。 关键在于,都像超融合系统这样,服务器直接把存储“招安”了,EMC的存储系统硬件怎么办?我们从其早些时候发布的Symmetrix VMAX3上可以看出一些端倪。 EMC在2009年初推出Symmetrix VMAX,由PowerPC平台(Symmetrix DMX)转向英特尔至强的怀抱,加上早就“投靠”英特尔的CLARiiON(现VNX),收购来的Data Domain、Isilon更是在商用硬件(通常意味着x86服务器)上体现软件价值的新一代,所以,EMC很早就宣称,硬件产品全部采用英特尔处理器。 不过,对于大多数存储系统而言,计算资源主要用在数据调度上,如自动精简配置、自动分层存储等提高存储效率的功能,对CPU的要求并不高,像头两代VMAX,CPU既不紧跟潮流,也不是同系列中顶级的,内存容量(从服务器的角度看)不算大,采用RapidIO这样的通信协议互连(通信与存储关系很近),还是比较典型的存储系统设计。 VMAX3则不然,最高的VMAX 400K采用了当时顶级的至强E5-2697 v2,(每Director,相当于控制器)1TB内存,互连换成更“计算”范儿的56Gbps InfiniBand,以至强E5服务器论的话算很高的配置了,依稀有Exadata的影子。再加上最多5760个驱动器,如果只用来做一个传统的存储系统,实在是太浪费了…如果在引擎(由一对Director组成)里跑些应用,即让计算靠近存储,才是正道。 
EMC Symmetrix VMAX3的核心硬件配置很“服务器”导向 VMAX3也可以被视为一种(超)融合系统?这绝非是妄自猜度EMC的想法,实际上有很多具体的论据支撑,这里就先不展开了…年底我们的2014版数据中心技术报告里,会有专门的剖析等着你! 作者:狒哥
| 





 发表于 2-18 16:02
发表于 2-18 16:02
