|
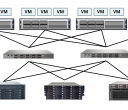
Translators 如前所述,Translators是GlusterFS提供的一种强大文件系统功能扩展机制,这一设计思想借鉴于GNU/Hurd微内核操作系统。GlusterFS中所有的功能都通过Translator机制实现,运行时以动态库方式进行加载,服务端和客户端相互兼容。GlusterFS 3.1.X中,主要包括以下几类Translator: (1) Cluster:存储集群分布,目前有AFR, DHT, Stripe三种方式 (2) Debug:跟踪GlusterFS内部函数和系统调用 (3) Encryption:简单的数据加密实现 (4) Features:访问控制、锁、Mac兼容、静默、配额、只读、回收站等 (5) Mgmt:弹性卷管理 (6) Mount:FUSE接口实现 (7) Nfs:内部NFS服务器 (8) Performance:io-cache, io-threads, quick-read, read-ahead,stat-prefetch, sysmlink-cache, write-behind等性能优化 (9) Protocol:服务器和客户端协议实现 (10)Storage:底层文件系统POSIX接口实现 这里我们重点介绍一下Cluster Translators,它是实现GlusterFS集群存储的核心,它包括AFR(Automatic File Replication)、DHT(Distributed Hash Table)和Stripe三种类型。 AFR相当于RAID1,同一文件在多个存储节点上保留多份,主要用于实现高可用性以及数据自动修复。AFR所有子卷上具有相同的名字空间,查找文件时从第一个节点开始,直到搜索成功或最后节点搜索完毕。读数据时,AFR会把所有请求调度到所有存储节点,进行负载均衡以提高系统性能。写数据时,首先需要在所有锁服务器上对文件加锁,默认第一个节点为锁服务器,可以指定多个。然后,AFR以日志事件方式对所有服务器进行写数据操作,成功后删除日志并解锁。AFR会自动检测并修复同一文件的数据不一致性,它使用更改日志来确定好的数据副本。自动修复在文件目录首次访问时触发,如果是目录将在所有子卷上复制正确数据,如果文件不存则创建,文件信息不匹配则修复,日志指示更新则进行更新。 DHT即上面所介绍的弹性哈希算法,它采用hash方式进行数据分布,名字空间分布在所有节点上。查找文件时,通过弹性哈希算法进行,不依赖名字空间。但遍历文件目录时,则实现较为复杂和低效,需要搜索所有的存储节点。单一文件只会调度到唯一的存储节点,一旦文件被定位后,读写模式相对简单。DHT不具备容错能力,需要借助AFR实现高可用性, 如图5所示应用案例。 Stripe相当于RAID0,即分片存储,文件被划分成固定长度的数据分片以Round-Robin轮转方式存储在所有存储节点。Stripe所有存储节点组成完整的名字空间,查找文件时需要询问所有节点,这点非常低效。读写数据时,Stripe涉及全部分片存储节点,操作可以在多个节点之间并发执行,性能非常高。Stripe通常与AFR组合使用,构成RAID10/RAID01,同时获得高性能和高可用性,当然存储利用率会低于50%。 图5 GlusterFS应用案例:AFR+DHT
作者:刘爱贵
| 





 发表于 2-12 08:35
发表于 2-12 08:35

